"Proper Unicode Support" and VAST

| Loading... |
| Reply to author |
| Edit post |
| Move post |
| Delete this post |
| Delete this post and replies |
| Change post date |
| Print post |
| Permalink |
| Raw mail |
       |
"Proper Unicode Support" and VAST

689 posts
|
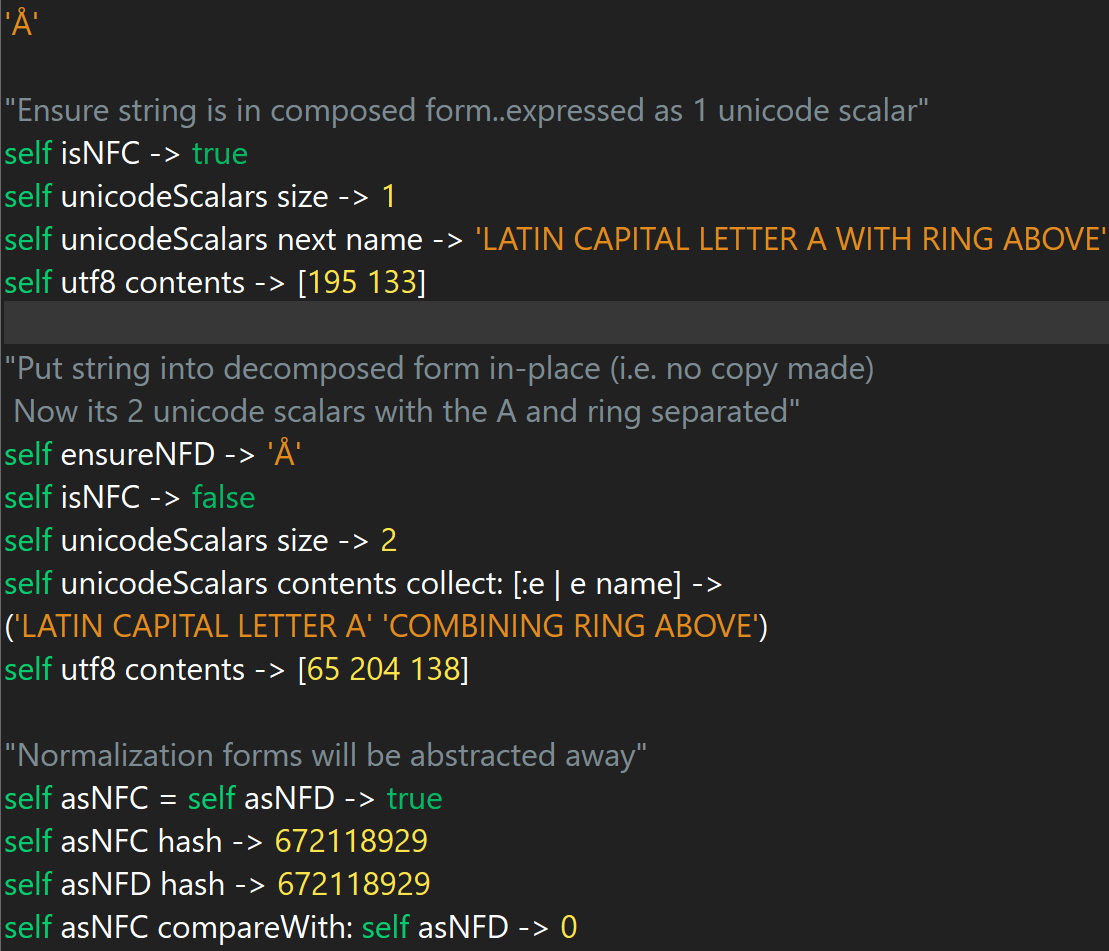
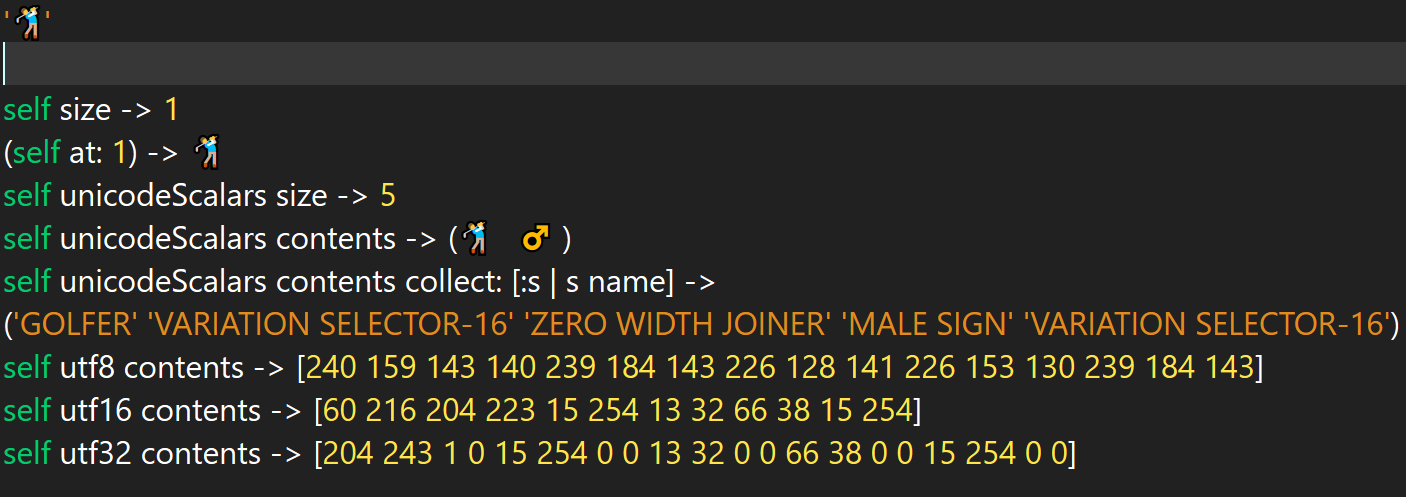
Hello All, Happy New Year to everyone! At Instantiations, we're certainly looking forward to 2021. First and foremost, the release of VAST Platform 2021 is on our minds. We're putting the finishing touches on it now and preparing to release it soon! After this release, one of the next important VAST additions is support for Unicode. I recently hinted at our "Unicode Support" coming to VAST Platform 2022 in this post: https://groups.google.com/u/1/g/va-smalltalk/c/sG3x1rBBU-E. Much exciting work has been done in this area in just the past couple months, and I wanted to share some of it with you. We're also planning to do a webinar at a later point this year to more formally demonstrate what has been developed. So how does one define "Unicode Support"? This is an important question to ask because the answer can vary widely. It is not a binary choice of "having Unicode" or "not having Unicode". In fact, I liked the way Joachim framed it in the aforementioned post as "Proper Unicode Support''. Thinking about it in terms of it being "proper" support provides a great frame of reference. (Some programming languages refer to this as "Unicode-correctness".) To me, "Proper Unicode Support" means functionality integrated into the product such that many of the various concepts in the Unicode standard are available as first-class objects in VAST. I also think "proper" support within VAST means automatically handling many of the complex issues that occur when using Unicode. (Most languages force the user to deal with these issues.) To meet the above criteria, we've been moving forward with an ambitious implementation that will provide a set of Unicode-related features that only languages like Swift, Raku (Perl 6), and Elixir will have parity with to date. What needed to change inside the VAST Platform? Unicode Support is truly not a single feature. We've been working towards "Proper Unicode Support" in VAST for many years through the continuing development of the many prerequisites. It's this group of prerequisite features that come together to make Unicode work properly and holistically. It's important to note that these new features are absolutely essential. After all, VAST was initially designed at a time when Unicode was just being standardized and almost everyone still operated using single-byte character set encodings. Some of these foundational features included reorganizing, fixing, and improving our code page converter. We also had to develop the capability for UTF-8 encoded filenames in our zip streams. Even the internals of our new OsProcess framework, both in the VM and in the image, were also designed with UTF-8 encoding by default. However, many features beyond this are still required to create the necessary foundation. What are some of the technical considerations? Many of you can attest (perhaps better than myself) to all the complexities with the digital representation and transmission of the world's languages. Issues are not magically solved because some bytes were thrown into a Unicode string. The concept of a "character" itself is a complex topic when considered across the spectrum of all languages. Even with Unicode, users still face issues with encodings, either off-the-wire or via the filesystem. Endianness in some of the encoded forms (like UTF-16LE or UTF-16BE) can become an issue also. New complexity is introduced with normalization forms since there are many "user-perceived" characters that can have several different codepoint representations (like Å vs Å, see screenshot below). As mentioned, ambiguity regarding what a "character" is and how you can access it from a string can be involved. Even the Unicode standard's usage of the term "character" is not consistent. For further reading, there is an interesting history regarding ANSI, regional character encodings, and the Unicode standard. If you are interested, I recommend books such as O'Reilly's "Unicode Explained" and "Fonts and Encodings". Looking at the history of various generations of programming languages with regards to digital language representation is also fascinating and enlightening. What are some of the features being added to VAST? VAST Platform (Current State) The following is a very brief overview of the relevant abstractions in the existing VAST system.
VAST Platform with Unicode Core (NEW -- Coming to VAST 2022) There are three main abstractions that we have developed to facilitate working with Unicode data which are the Unicode counterparts to the locale-based String/Character. They are: UnicodeScaler, Grapheme, UnicodeString.
Other New Features
Beyond this, we have some follow-on work that we'll be integrating into VAST Platform 2022, namely, support for Literals, upgraded Scintilla editor with UTF-8 encoding by default, File System APIs, and Windows Wide APIs. I realize this was a huge amount of information to digest, so thank you for reading it. That said, there's more to come! We look forward to showing our customers and the community these new features during a live webinar in the coming months! -Seth --You received this message because you are subscribed to the Google Groups "VA Smalltalk" group. To unsubscribe from this group and stop receiving emails from it, send an email to [hidden email]. To view this discussion on the web visit https://groups.google.com/d/msgid/va-smalltalk/3252d176-9751-4cc5-ad86-f662f292597cn%40googlegroups.com. |


| Loading... |
| Reply to author |
| Edit post |
| Move post |
| Delete this post |
| Delete this post and replies |
| Change post date |
| Print post |
| Permalink |
| Raw mail |
| |
Re: "Proper Unicode Support" and VAST
|
300 posts
|
Seth, This is amazing. I chatted a lot with Mariano about Unicode and the scope of the support you're willing to provide is outstanding. So, congrats to the team for all the good work both in VAST 2021 release (that its looking really great) and the future 2022 one. Regards, Gabriel On Saturday, January 16, 2021 at 6:03:30 PM UTC-3 Seth Berman wrote:
... [show rest of quote] You received this message because you are subscribed to the Google Groups "VA Smalltalk" group. To unsubscribe from this group and stop receiving emails from it, send an email to [hidden email]. To view this discussion on the web visit https://groups.google.com/d/msgid/va-smalltalk/7067cd30-3b1d-441d-b1ee-b7105a7d7673n%40googlegroups.com. |
| Loading... |
| Reply to author |
| Edit post |
| Move post |
| Delete this post |
| Delete this post and replies |
| Change post date |
| Print post |
| Permalink |
| Raw mail |
| |
Re: "Proper Unicode Support" and VAST
|
1922 posts
|
In reply to this post by Seth Berman
HI Seth, Happy new year to all at Instantiations and everybody on this list! It is good to see how much effort and energy you are putting into Unicode. I am in the last third or our endless journey to UTF-8 with our Seaside-App. We've seen many pitfalls and frustrations along the way and had so many surprises that my respect for this area has grown tremendously over the years ;-) I've learned that we won't see any platform or language that will just seemlessly support Unicode, even if some things seem easy or "just solved" in, say, Java or Python. What started as a simple "just convert whatever comes in to the image to ISO-8859 and concert everything going out to the Browser to UTF-8" ended in an endless mess of handling edge cases or areas like NFD and NFC and whatnot that I had never heard or nightmare'd of. Keeping the server side String comparisons with JavaScript String comparison in the Browser and whatnot. It all starts with simple questions like "how long is a varchar in DB2 when it should store Uncode Strings made up of up to X "letters" ?". And I somewhat have the feeling we haven't even touched any hard problems. What you describe sounds like a much broader attempt to solve Unicode problems than what is avaliable in any mainstream programming languages. This is good news! I can hardly wait for 2021 to end ;-) And there will even be a lot of nice improvements in VAST 2021... Keep up the good work that you and the development and support team at Instantiations has been doing for years now. Every release since 7.5 was a grab bag of great leaps forward, and to me it feels like the pace at which even better things come out is increasing. I am currently working on a customer's code base in VisualAge 6 and help migrate it to 9.2.2. It is astonishing how much VA Smalltalk has evolved since the IBM days ... Joachim Seth Berman schrieb am Samstag, 16. Januar 2021 um 22:03:30 UTC+1:
... [show rest of quote] You received this message because you are subscribed to the Google Groups "VA Smalltalk" group. To unsubscribe from this group and stop receiving emails from it, send an email to [hidden email]. To view this discussion on the web visit https://groups.google.com/d/msgid/va-smalltalk/98861098-c55e-432d-b80f-00a28caa9a90n%40googlegroups.com. |
| Loading... |
| Reply to author |
| Edit post |
| Move post |
| Delete this post |
| Delete this post and replies |
| Change post date |
| Print post |
| Permalink |
| Raw mail |
| |
Re: "Proper Unicode Support" and VAST
|
689 posts
|
Hi Gabriel, Joachim
Thanks for the encouraging feedback, I'm certainly glad to hear you are excited about the direction! - Seth On Monday, January 18, 2021 at 3:00:50 AM UTC-5 [hidden email] wrote:
... [show rest of quote] You received this message because you are subscribed to the Google Groups "VA Smalltalk" group. To unsubscribe from this group and stop receiving emails from it, send an email to [hidden email]. To view this discussion on the web visit https://groups.google.com/d/msgid/va-smalltalk/b8941bdd-9b45-4676-a46b-6b3a0c1b87e3n%40googlegroups.com. |
| Loading... |
| Reply to author |
| Edit post |
| Move post |
| Delete this post |
| Delete this post and replies |
| Change post date |
| Print post |
| Permalink |
| Raw mail |
| |
Re: "Proper Unicode Support" and VAST
|
2989 posts
|
In reply to this post by Seth Berman
Hello Seth Someone has been busy :-) UnicodeString The choice to go with graphemes as the primary abstraction is a bold one, as you said few languages use this. There is risk and opportunity here. For text processing it is most likely what users would expect as can be demonstrated by reversing a string with an emoji with a skin tone (👍🏼) or country flag (🇩🇲). I assume #size would answer the number of graphemes. As most external systems (XSD, RDMS, ...) will likely use code points or worse "Unicode code units" users will have to remember to use the correct selector. Views How are they different from encoding and decoding support? Is this orthogonal to encoding and decoding support? Copy-On-Write Did you consider making strings immutable? If so what were some of the considerations? Was there just too much code that expects strings to be mutable? Philippe On Saturday, January 16, 2021 at 10:03:30 PM UTC+1 Seth Berman wrote:
... [show rest of quote] You received this message because you are subscribed to the Google Groups "VA Smalltalk" group. To unsubscribe from this group and stop receiving emails from it, send an email to [hidden email]. To view this discussion on the web visit https://groups.google.com/d/msgid/va-smalltalk/045ae40c-9981-421b-8000-8d7fab751db4n%40googlegroups.com. |
| Loading... |
| Reply to author |
| Edit post |
| Move post |
| Delete this post |
| Delete this post and replies |
| Change post date |
| Print post |
| Permalink |
| Raw mail |
| |
Re: "Proper Unicode Support" and VAST
|
689 posts
|
Greetings Philippe, Thanks for these questions and good to hear from you. UnicodeString "Someone has been busy :-)" "There is risk and opportunity here" "I assume #size would answer the number of graphemes." "As most external systems (XSD, RDMS, ...) will likely
use code points or worse "Unicode code units" users will have to
remember to use the correct selector."
Views "How are they different from encoding and decoding
support? Is this orthogonal to encoding and decoding support?" "Did you consider making strings immutable? If so, what
were some of the considerations? Was there just too much code that expects
strings to be mutable?" Additional Information Certainly, there is a whole other list of challenges regarding coexistence with String and Character, but they are not as interesting to hear about, and my initial post in this thread was getting rather long. These challenges would not be unique to us and a lot of preparation for this task was done by researching the lessons-learned from various languages that have been augmented with Unicode, such as Delphi and Python 2. What we will not be doing is a Python 3-like transition where our existing String and Character just, all the sudden, become Unicode. That would be a disaster in VAST on so many levels. I do not know if the choice of making the basic unit an extended grapheme cluster was bold or not. What bothered me most about any other representation was how the Collection APIs would have the potential to just fall apart on you. It reminded me of what might happen if one viewed a collection of Integers as a bunch of indexable bytes. Sure, if all the integer values are < 256, this is going to seamlessly work out for everyone. Until it doesn't. So, a 'byte' probably is not really the appropriate way to canonically view a collection of Integers. Likewise, when working with the Collection API, it just did not seem appropriate to force the user to work with only part of what they probably consider a character to be. It certainly creates a lot more work for them to use the Collection API appropriately and correctly. There are always UnicodeString representational exceptions, which is why we created performant views. Many thanks for your questions Phillipe, I look forward to hopefully seeing you at a future ESUG event. - Seth On Friday, January 22, 2021 at 7:09:41 AM UTC-5 [hidden email] wrote:
... [show rest of quote] You received this message because you are subscribed to the Google Groups "VA Smalltalk" group. To unsubscribe from this group and stop receiving emails from it, send an email to [hidden email]. To view this discussion on the web visit https://groups.google.com/d/msgid/va-smalltalk/d4331a3e-cd2b-4184-83ed-28f694c82ed8n%40googlegroups.com. |
| Loading... |
| Reply to author |
| Edit post |
| Move post |
| Delete this post |
| Delete this post and replies |
| Change post date |
| Print post |
| Permalink |
| Raw mail |
| |
Re: "Proper Unicode Support" and VAST
|
2989 posts
|
Hello Seth On Friday, January 22, 2021 at 6:34:24 PM UTC+1 Seth Berman wrote: ... Since all the optimization went into this I wonder if at one point users will start asking for CP-1252 views or similar for efficient access and then you'll have to maintain two encoding and decoding stacks.
I see, I assumed as much. .... I believe going against established consensus and conventional wisdom among 20+ year old programming languages is bold. The risk is that you don't do what users expect, miss something or otherwise point yourself into a corner. Additionally backwards compatibility and migration always add a unique challenge. The opportunity is that users accept it as "the correct thing" ™ and see it as superior and forward looking.
Same here. Thank you for taking the time to answer my questions. Cheers Philippe You received this message because you are subscribed to the Google Groups "VA Smalltalk" group. To unsubscribe from this group and stop receiving emails from it, send an email to [hidden email]. To view this discussion on the web visit https://groups.google.com/d/msgid/va-smalltalk/dda55e4f-e9b1-47f8-91a4-b40d298f503an%40googlegroups.com. |
| Loading... |
| Reply to author |
| Edit post |
| Move post |
| Delete this post |
| Delete this post and replies |
| Change post date |
| Print post |
| Permalink |
| Raw mail |
| |
Re: "Proper Unicode Support" and VAST
|
689 posts
|
" Since all the optimizations went into this I wonder if at one point users will start asking for CP-1252 views or similar for efficient access and then you'll have to maintain two encoding and decoding stacks." - From my standpoint, if customers continue to invest
in the product and ask for such things, then we will be happy to do it. Maybe
more to your meaning from an implementation point of view, I haven't really
talked much about the fact that the Unicode algorithms are implemented almost exclusively
in Rust. Rust has genuinely nice native Unicode support modelled
appropriately for a system-level programming language and a super-trim runtime
that we link in. We make use of their various 'crates' to help us get the
functionality we need, and my sincere goal is to be able to hand back to that
community like we did with Dart. In regard to your comment, I would
be taking a strong look at crates like 'encoding_rs' to
get that kind of functionality for our customers. "I believe going against established consensus and conventional wisdom among 20+ year old programming languages is bold." - That sounds ominous:) But I understand your meaning and it
is undeniably something that had to be thought about. We find ourselves
in the unusual position that we are a 20+ year old programming language that
currently has near zero formal support for Unicode, and we're just now
implementing it. There is a whole era of languages that had to make those
decisions long ago and chose things like UCS-2 as internal representations and
indexing decisions based off that. Time went on and lessons were learned
about the inadequacies of UCS-2, compatibility was likely a top goal and UTF-16
enters the picture. Their indexing strategy was probably set-in stone at
that point. In the modern era, the more recent languages like Rust, Go, Julia,
Swift (only as of ver5 due to object-c baggage) choose UTF-8 internal representations.
Some that don't, like Dart, have their hands tied because of Javascript.
There is a growing departure away from placing such importance on constant time
indexing. We're seeing more complexity in the underlying structure of
Unicode 'characters' like emoji which undoubtedly puts more strain on codepoint
based implementations. So, in general, I think consensus and wisdom
in this area is still in motion and not established. But to be fair, you
said established consensus/conventional wisdom among 20+ year old
languages. To that I would say those eras of languages are not our
target for this new support. And I would wonder, if those languages had both the body of
knowledge and the Unicode standard as it exists today, would they still be
making the same choices? I think you are right, a grapheme-cluster based UnicodeString will have the potential to not do what is expected for everybody. This could be from a functional or performance point of view. We will work on optimizing the fast cases for it, but in the end, it’s not a byte string. But mostly, I believe the trade-offs to be favorable. We can abstract away normalization and character boundaries which I believe will be an ultimate win in this environment. I certainly don't believe in one-size-fits-all approaches. For example, Systems-level programming languages probably shouldn't use grapheme-cluster indexing by default. It’s not that way in Rust and I wouldn't expect. Certainly, given a project of this magnitude, there are
going to be quite a few decisions that have been discussed that are going to
need adjustment (or abandonment) along the way. - Seth On Sunday, January 24, 2021 at 12:56:06 PM UTC-5 [hidden email] wrote:
... [show rest of quote] You received this message because you are subscribed to the Google Groups "VA Smalltalk" group. To unsubscribe from this group and stop receiving emails from it, send an email to [hidden email]. To view this discussion on the web visit https://groups.google.com/d/msgid/va-smalltalk/2f9fcf86-9fff-406c-91e5-4f2fdd81f3acn%40googlegroups.com. |
| Free forum by Nabble | Edit this page |